1편에서는 카카오API를 이용해서 원하는 keyword의 블로그의 타이틀과 링크 데이터를 가져왔다.
파이썬 카카오 검색 API 활용 웹스크래핑 (tistory.com)
파이썬 카카오 검색 API 활용 웹스크래핑
카카오 API 사용해서 웹스크래핑 해보기 네이버 만큼 친절하진 않았지만... 그렇다! 우린 카카오 검색 api 를 사용해서 웹스크래핑을 할 수 있다! Kakao Developers Kakao Developers 카카오 API를 활용하여
wookdata.tistory.com
2편에서는 가져온 링크들 중에서 네이버블로그 링크만 추출하여 동적웹스크래핑을 진행하였다.
파이썬 카카오 검색 API 활용 웹스크래핑(2) (tistory.com)
파이썬 카카오 검색 API 활용 웹스크래핑(2)
파이썬 카카오 검색 API 활용 웹스크래핑 (tistory.com) 파이썬 카카오 검색 API 활용 웹스크래핑 카카오 API 사용해서 웹스크래핑 해보기 네이버 만큼 친절하진 않았지만... 그렇다! 우린 카카오 검색
wookdata.tistory.com
위 과정을 통해 네이버 블로그 본문 텍스트 데이터를 추출하였다.
이번 시간에는 카카오API를 이용해 가져온 Link를 통해, Tistory 본문 텍스트 데이터를 추출해보자!
import re
from bs4 import BeautifulSoup
import urllib.request
## tistory 블로그 링크 추출
p = re.compile('https?://[a-zA-Z0-9_-]+\.tistory\.com/\d+')
t_links = p.findall(text)
print(t_links)정규표현식을 사용해서 위 코드를 돌리면 tistory 링크들이 뽑힌다.

잘 뽑혀진 것을 확인했으니, Beautifulsoup로 정적 웹스크래핑을 진행해보면...
## 데이터 가져오기 시험
t_link = t_links[4] #그냥 4로 해봤다
html = urllib.request.urlopen(t_link)
bs_obj = BeautifulSoup(html, 'html.parser')
bs_obj
이런식으로 본문 데이터가 그대로 존재한다!
후에, 본문이 있었던 곳의 html을 파악한 후 코드를 실행한다.
## 본문 텍스트 데이터 추출
## 해당 <div> 태그 찾기
div_tag = bs_obj.find('div', class_='tt_article_useless_p_margin contents_style')
## <div> 태그와 그 하위 요소에 포함된 텍스트를 추출
text_data = div_tag.get_text(strip=True)
print(text_data)
와우! 텍스트 데이터가 잘 뽑혀진 것을 확인할 수 있었다.
그럼, 반복문을 이용해서 텍스트 데이터를 왕창 가져와보자
text_data_list = [] # 텍스트 데이터를 저장할 리스트
valid_urls = [] # 유효한 URL을 저장할 리스트
for url in t_links:
response = requests.get(url)
bs_obj = BeautifulSoup(response.text, 'html.parser')
div_tag = bs_obj.find('div', class_='tt_article_useless_p_margin contents_style')
## NUll값이 존재했기 때문에 시행
if div_tag is not None:
text_data = div_tag.get_text(strip=True)
text_data_list.append(text_data)
valid_urls.append(url)
## 판다스로 데이터 프레임 생성 및 NULL값 제거
df = pd.DataFrame({'URL': valid_urls,'Text Data': text_data_list})
df.dropna(subset=['Text Data'], inplace=True)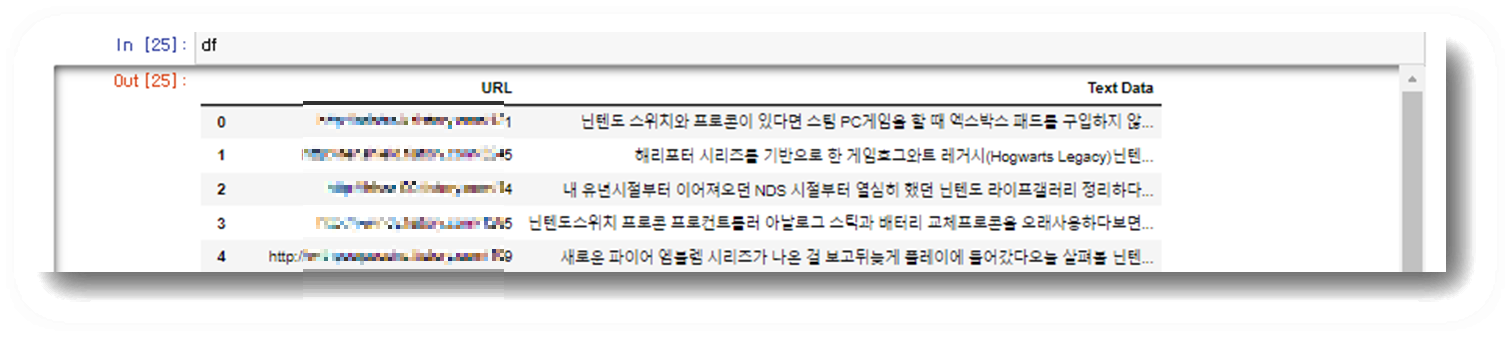
너무 너무 너무!!! easy하다.
위 내용은 정말 예전에 해놓은건데... 텍스트 강의 A+ 맞은 기념으로 올린다... 사실 논문 읽기 귀찮을 때 정리하는거다.
다음에는 유튜브api 사용해서 원하는 키워드의 영상을 검색, 댓글(대댓글)을 가져오는 코드를 보여주도록 하겠다.
그리고 그 악랄하다는 한국어 전처리를 진행해보도록 하자...
'데이터사이언스 대학원 생활 > TextAnalytics' 카테고리의 다른 글
| 파이썬 유튜브(Youtube)API 활용 /원하는 키워드 영상 댓글 추출 (0) | 2023.07.14 |
|---|---|
| 파이썬 카카오 검색 API 활용 웹스크래핑(2) (0) | 2023.06.13 |
| 파이썬 카카오 검색 API 활용 웹스크래핑 (0) | 2023.05.26 |
| Selenium 설치 방법 (0) | 2023.03.20 |
| 정규 표현식(Regular Expression) (0) | 2023.03.14 |