Human3.6M은 유료이지만, 최근까지도 많은 2D, 3D Human Pose Estimation 논문들이 모델을 검증할 때 사용한다.
그리고 앞으로도 널리 사용될 것으로 보인다.
근데 이 데이터셋... 상당히 용량이 크고 파일이 나눠져있어,
다운로드하고 원하는 대로 바꾸기 상당히 번거롭다는 단점이 존재한다.
이를 해결하기 위해 도커를 사용해서 쉽고 빠르게 환경 구성을 한 후 다운로드를 해보자!
Human3.6M
http://vision.imar.ro/human3.6m/description.php
Human3.6M Dataset
Diversity and Size • 3.6 million 3D human poses and corresponding images • 11 professional actors (6 male, 5 female) • 17 scenarios (discussion, smoking, taking photo, talking on the phone...) Accurate Capture and Synchronization • High-resolution
vision.imar.ro
0. 필자의 환경
OS: Ubuntu 20.04
Human3.6M 아이디 보유(유료)
1. Docker 다운로드
나중에 도커 다운로드 하는 방법을 따로 정리하겠지만,
일단 나는 구글링을 통해 우분투 20.04 환경에 docker를 다운로드했다.
https://ko.linux-console.net/?p=755#gsc.tab=0
Ubuntu 20.04에서 Docker를 설치하고 사용하는 방법
Ubuntu 20.04에서 Docker를 설치하고 사용하는 방법 Docker는 개발자와 시스템 관리자가 컨테이너로 애플리케이션을 빌드, 실행 및 공유할 수 있는 가장 인기 있는 오픈 소스 플랫폼입니다. 컨테이너가
ko.linux-console.net

도커를 다운로드하는 이유는 아래에 설명하겠다.
2. Human3.6M 데이터세트를 사용하기 쉬운 상태로 다운로드하기
https://github.com/anibali/h36m-fetch
GitHub - anibali/h36m-fetch: Human 3.6M 3D human pose dataset fetcher
Human 3.6M 3D human pose dataset fetcher. Contribute to anibali/h36m-fetch development by creating an account on GitHub.
github.com
Human3.6M Dataset를 직접 다운로드하는 경우 상당한 용량, 논문이 원하는 형태로 다운로드를 해야 하는 경우가 많다.
이를 해결하기 위해 도커(Docker)를 사용한다.
도커(Docker)를 사용하면 Human3.6M의 이미지와 주석을 쉽게 다운로드, 추출 및 전처리할 수 있다.
(1) git clone, 저장소로 이동
$ git clone https://github.com/anibali/h36m-fetch.git
$ cd h36m-fetch저장소 안에 도커 파일이 있기 때문에 이를 활용하고자 한다.
(2) 도커 서비스 시작 및 활성화 확인
$ sudo service docker start
$ sudo service docker status
(3) docker-compose 실행
Docker compose에서는 compose 파일을 준비하여 커맨드를 1회 실행하는 것으로,
그 파일로부터 설정을 읽어 들여 모든 컨테이너 서비스를 실행시키는 것이 가능
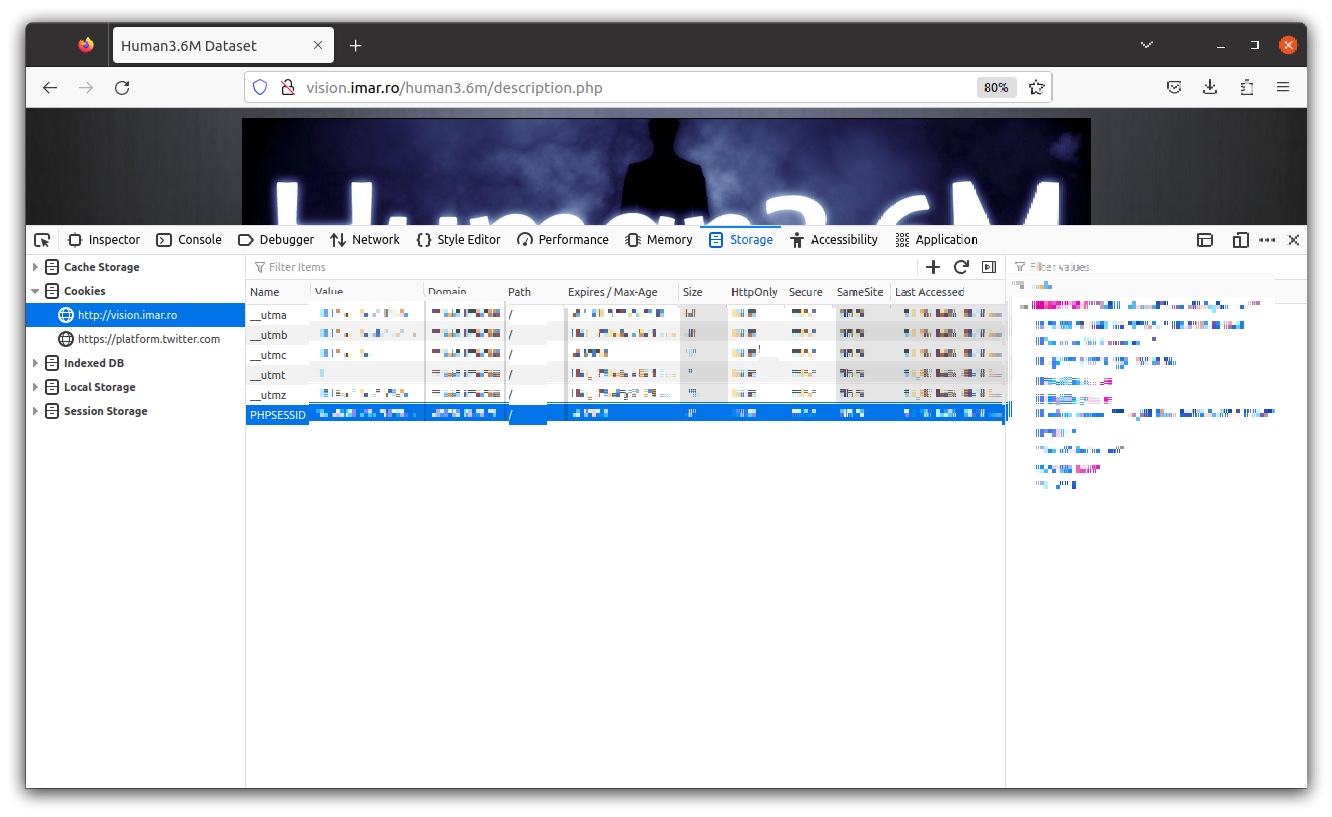
$ sudo docker-compose up(4) Human3.6M 로그인 및 PHPSESSID 찾기
로그인 후에, 개발자 도구 안의 쿠키로 들어가서 PHPSESSID값을 구한다.
(5) 데이터 다운로드 및 전처리
PHPSESSID값을 알아냈다면, 스크립트를 사용하여
download_all.py 데이터세트를 다운로드하고,
extract_all.py 다운로드한 아카이브를 추출하고,
process_all.py 데이터세트를 사용하기 쉬운 형식으로 전처리한다.
$ docker-compose run --rm --user="$(id -u):$(id -g)" main python3 <script>
<script> 부분만 바꿔서 사용하면 된다.
하나하나 상당한 시간이 소요된다.
3. 결과
1. 다운로드
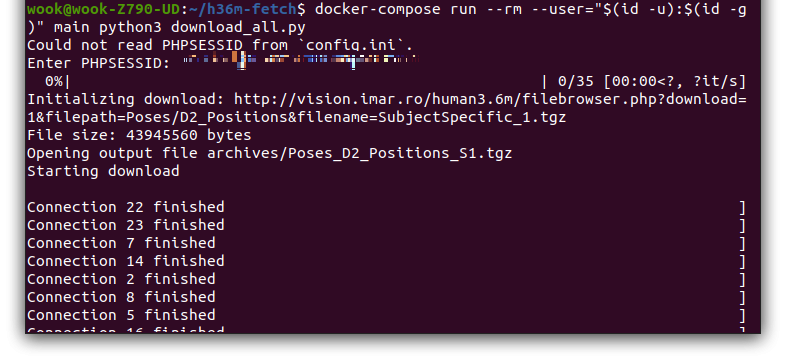
$ docker-compose run --rm --user="$(id -u):$(id -g)" main python3 download_all.py
이 스크립트는 Human3.6M 데이터셋의 여러 파일을 다운로드하기 위해 작성되었다.
이 데이터셋은 http://vision.imar.ro/human3.6m/에서 호스팅 되고 있으며, 스크립트는 이 웹사이트에서 파일을 다운로드하고,
다운로드한 파일의 무결성을 검증한다.
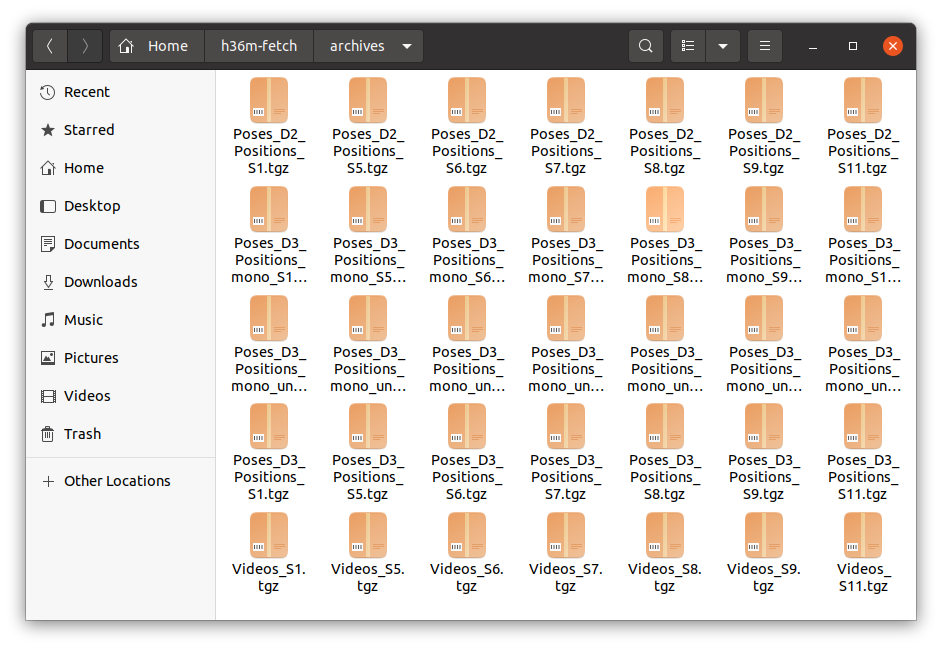
위의 코드를 돌리면 아래와 같이 archives 폴더가 생성된다.
파일은 .tgz 형태로 다운로드된다.
2. 압축 해제
$ docker-compose run --rm --user="$(id -u):$(id -g)" main python3 extract_all.py
이 Python 스크립트는 주어진 .tgz (tarball) 파일들을 압축 해제하는 과정을 자동화한다.
각각의 .tgz 파일은 특정 데이터셋(여기서는 Human3.6M 데이터셋의 일부)의 구성 요소를 포함한다.
스크립트는 이러한 파일들을 지정된 디렉터리 구조에 맞게 압축 해제한다.
위 코드를 돌리면 extracted 폴더가 생성된다.
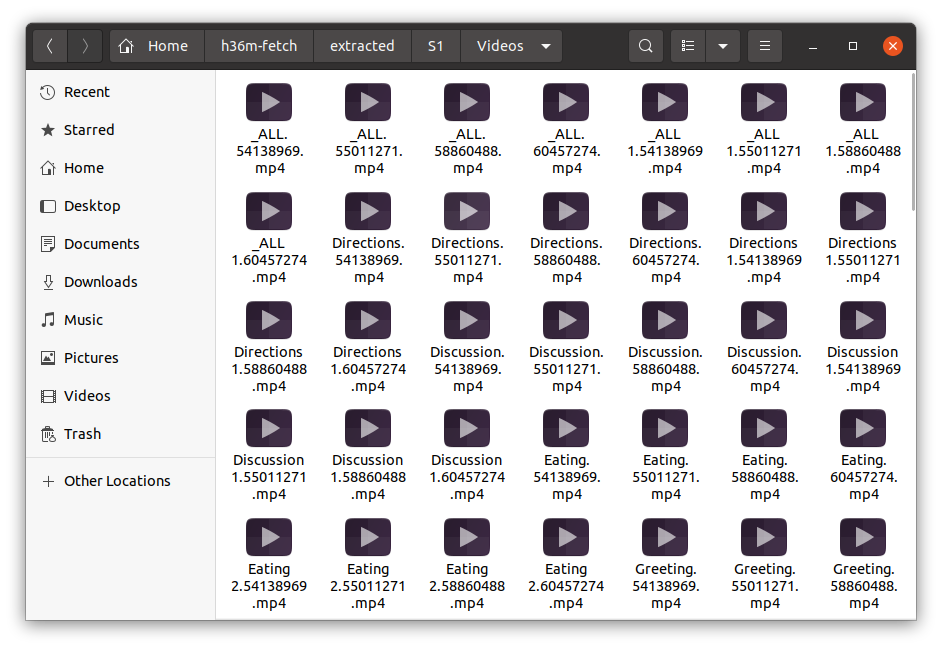

3. 전처리
$ docker-compose run --rm --user="$(id -u):$(id -g)" main python3 process_all.py
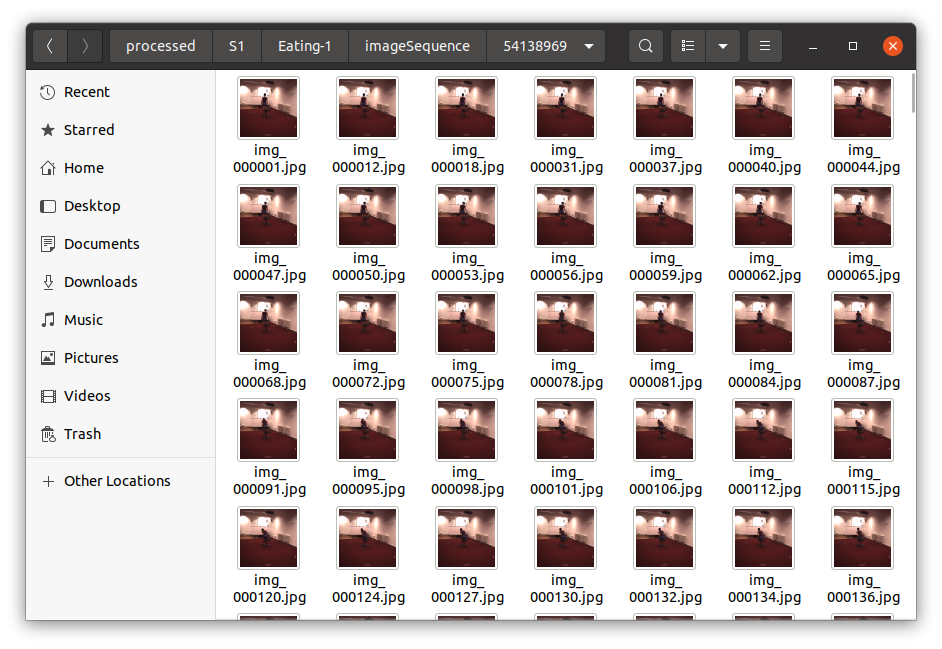
이 Python 스크립트는 Human3.6M 데이터셋의 비디오 및 포즈 데이터를 처리하고 정리하는 복잡한 프로세스를 수행한다.
데이터셋에서 2D 및 3D 포즈 정보를 추출하고, 이를 사용하여 카메라 내부 매개변수를 추론하며,
비디오에서 특정 프레임을 추출하여 모든 정보를 통합된 형식으로 저장한다.
✩ 프레임 샘플링 방식은 데이터 전처리 단계에서 모든 프레임을 선택하지 않는 것을 기반으로 한다. ✩
이는 "Compositional Human Pose Regression"에서 언급된 Protocol #2 설정을 사용한다고 가정한다.
이에 따라 다음과 같은 방식으로 프레임을 선택한다:
- 테스트 대상자(S9와 S11): 이 스크립트는 64번째마다 하나의 프레임을 사용합니다. 이는 테스트 대상자에 대해 더 적은 수의 프레임을 사용함으로써, 포즈 추정 모델의 성능 평가를 위해 충분할 것이라고 가정한다.
- 훈련 대상자(S1, S5, S6, S7, S8): "흥미로운" 프레임만 선택합니다. 즉, 활동이나 움직임이 적은 기간 동안 거의 동일한 프레임을 건너뜁니다. 이는 훈련 데이터에서 중복되거나 정보가 적은 프레임을 줄이는 데 도움이 된다.
프레임 선택 전략 변경
이러한 행동을 변경하고 싶다면 process_all.py 스크립트의 select_frame_indices_to_include() 함수를 수정할 수 있다.
예를 들어, 특정 대상자에 대해 더 많은 프레임을 포함시키거나 "흥미로운" 프레임을 결정하는 기준을 변경할 수 있다.
- 샘플링 속도 변경: 테스트 대상자의 경우, 64번째 프레임을 사용하는 대신 다른 간격을 선택할 수 있다.
- 움직임 임계값 조정: 훈련 대상자의 경우, 프레임이 "흥미로운" 것으로 간주되는 움직임의 임계값(현재는 40mm로 설정)을 조정할 수 있습니다. 이 값을 줄이면 더 많은 프레임이 선택되며, 늘리면 기준이 더 엄격해진다.
- 모든 대상자에 대한 균일한 샘플링: 모든 대상자에 대해 동일한 프레임 선택 전략을 적용하려면 테스트 대상자나 훈련 대상자에 사용된 전략 중 하나를 모두에 적용할 수 있다.
- 데이터 분석에 기반한 맞춤형 기준: 데이터에 대한 구체적인 통찰이 있다면, 데이터셋의 특성이나 수행하려는 작업의 요구 사항에 더 잘 맞는 맞춤형 프레임 선택 전략을 개발할 수 있다.
'데이터사이언스 대학원 생활 > Human Pose Estimation' 카테고리의 다른 글
| [논문 리뷰] SMPL: A Skinned Multi-Person Linear Model (0) | 2023.07.12 |
|---|---|
| Openpose 설치 및 사용(Windows 버전으로 쉽게) (2) | 2023.06.28 |
| MMPose - 훈련된 모델로 포즈 추정 실행! (0) | 2023.06.24 |
| MMpose 사용해서 (COCO - 2D WholeBody Datasets) 데이터로 모델 학습까지! (0) | 2023.06.23 |
| MMPose 설치 방법 (0) | 2023.06.23 |